AWS Nitro Enclaves is a Trusted Execution Environment (TEE) implementation based on the AWS Nitro TPM security chip. It provides integrity and confidentiality guarantees for code and data running inside it where even the host instance running the enclave cannot tamper with the code or snoop into the data. These guarantees allow developers to securely outsource computation to third parties without fear of malicious behavior or data leaks and lie at the core of our Oyster platform.
The security does have a cost however. Enclaves have no connection to the outside world except a vsock interface that allows socket based communication with the host. This means any application that uses the network needs to be modified to use vsocks instead of IP sockets. This is easier said than done because any reasonably complex application uses networking libraries that assume the existence and usage of IP stacks. Networking libraries, especially high-level libraries like http servers/clients, that use vsocks are virtually non-existent in most languages. Simple command line utilities like curl and wget do not support vsock. Nor do essential programs like Caddy, Nginx, PostgreSQL, etc. All in all, rewriting applications and workflows to use vsocks is a gargantuan task.
Given this, we set out with one clear goal:
"Applications should be able to run inside enclaves unmodified."
This means enabling the following:
- A network interface that’s usable by enclave applications
- Ability to listen to incoming connections from within the enclave
- Ability to connect to other applications from within the enclave
- Ability to listen to incoming connections from the Internet
- Ability to connect to other endpoints on the Internet
Running Start
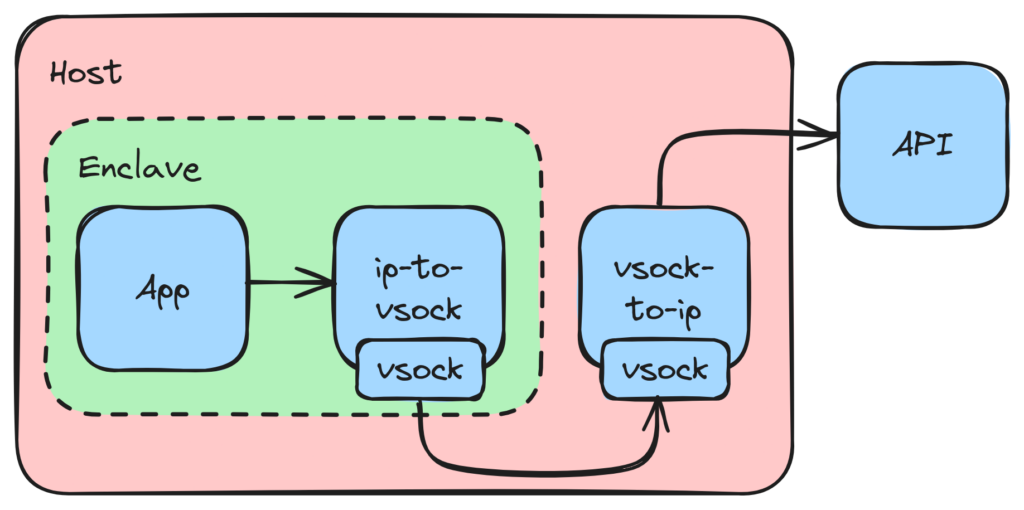
The AWS docs are invaluable for understanding the nuts and bolts of developing applications for enclaves. The basic idea is to run applications inside the enclave that are vsock aware and run some proxies on the outside to enable bidirectional communication with specific endpoints.
While this approach works for greenfield applications, it has a few obvious limitations:
- Existing applications not written with vsocks in mind cannot be run inside enclaves
- The proxy connects only to a specific endpoint, meaning you need multiple proxies to connect to multiple endpoints
- The proxy needs to know the endpoint beforehand; it cannot be determined at run time
For Oyster, we needed to do much better to make writing applications for enclaves a nice seamless experience for traditional non-enclave developers.
Manifesting an IP stack
The easiest part turned out to be ensuring an IP stack and route exist inside the enclave so that applications can bind to it and send packets
ifconfig lo 127.0.0.1
ip route add default dev lo src 127.0.0.1
The enclave already has all the mechanisms necessary (it is Linux after all), we just need to enable it. Mind you, at this stage, packets to the wider internet go nowhere. But, at least the applications do not crash or error out on doing even basic networking. Localhost networking does work, so that's something to work with.
Early proxies
Our initial approach was much like the AWS approach of using proxies to tunnel traffic to the internet, just with proxies inside the enclave as well.
While existing applications more or less "work" now, they still have the same proxy limitations - the proxies connect to one single endpoint known at build time and are therefore not general purpose.
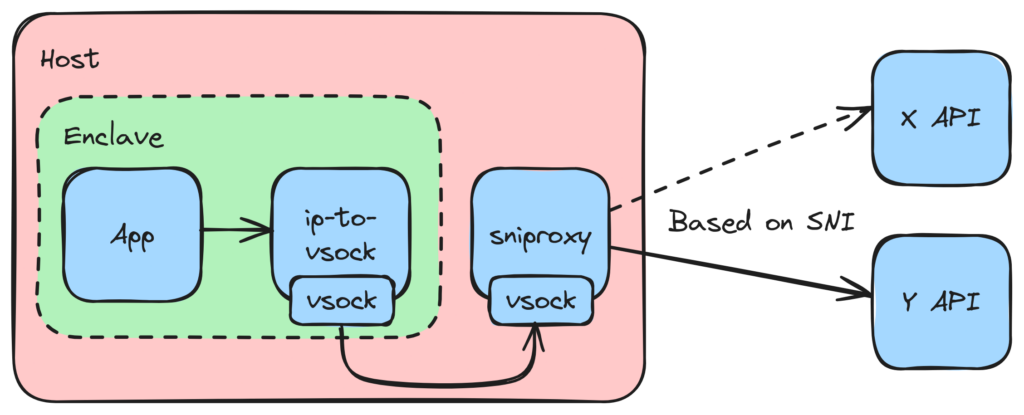
Generalizing proxies
We started to work on the proxy limitations by focusing on the most widely used protocol on the web by far - HTTPS. Our idea was to use the Server Name Indication (SNI) information to retrieve the domain being accessed at runtime whenever a new connection is initiated. We then perform a DNS lookup on the host and connect to the corresponding IP. Security is preserved by TLS as usual.
Turns out, somebody else already had the same idea (for some other use case presumably) and implemented it already! Some quick changes to make it compatible with vsocks and we're on our way. Open source ftw ♥️
We can now support HTTPS connections to arbitrary domains, but we faced quite a few issues:
- not every application is HTTP based, most blockchain nodes use TCP-based custom transport protocols, for example
- domain fronting is a thing, where applications knowingly lie about their SNI
- eSNI is on the horizon which puts an expiry date on being able to read the SNI in the proxy
Can we do better?
Going deeper
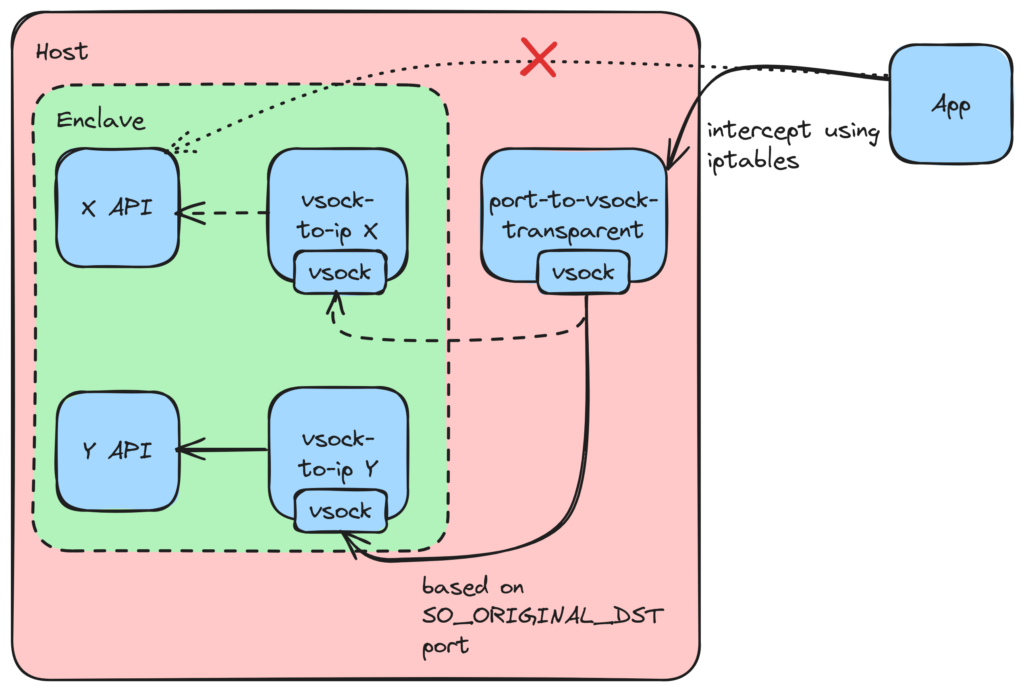
The next goal was for a general purpose TCP proxy, essentially combining the best of the last two approaches. The first thing that came to our mind as potential inspiration was Tor and SquidProxy since they aim to have similar interfaces.
To create a seamless transparent proxy, you need two things - intercept connections, and identify the original destination so you can proxy to it. The first part is quite trivial using iptables. The trick we found for the second part was the SO_ORIGINAL_DST machinery. Essentially whenever you redirect a connection using iptables, Linux stores the original destination of the connection. The SO_ORIGINAL_DST socket option can be used to fetch this destination and use it for proxying.
A similar setup works for clients wanting to reach servers running inside the enclave as well. This time, we use SO_ORIGINAL_DST to essentially implement port forwarding.
We now have general purpose proxies that work on the TCP level! These proxies entered production in our first base image, the Salmon family, and are used to this day. But as it turns out, we're nowhere near the end of our journey.
A word of caution
Enclaves do not have networking built in for a very good reason - to minimize the attack surface by having as simple a base system as possible. The absence of an IP stack protects against potential kernel vulnerabilities in the IP networking subsystem. It also encourages applications to be quite conservative in terms of communication and the inputs that they accept, thereby providing an extra layer of security. Introducing full-fledged networking changes the threat model and introduces the chance of a remote exploit against applications running in the enclave which might not need such capabilities. Connectivity vs security is a tradeoff at the end of the day and should be carefully considered.
In practice, most applications that are suitable for Oyster are fundamentally network applications, hence there should be no material change to the risk profile - this is similar to the risk you take already when exposing any service to the wider Internet. But this concern is why networking in Oyster is also optional, enclave developers can simply leave out proxy components that are not needed for their use case.
Onward.
TCP problems
As we found out while deploying some enclaves, our applications and libraries happen to do a lot of interesting things at the TCP level that completely break down with these proxies. The easiest to identify are connection timeouts - connections originating from applications within the enclave succeed almost instantly. No timeouts are carried forward through the proxy to the other side actually connecting to the endpoint.
Another one is endpoint unavailability. Connections from applications always succeed, the proxy eventually connects to the endpoint, figures out that it is unavailable and it then filters back to the application.
There are more subtle and esoteric issues lurking when you stray off the happy path, as we found out when trying to run an IPFS node for the Bonfida gateway. TCP connections can be half closed by either side of the connection which invites its own challenges when propagating it properly and transparently. More generally, it's tedious and error-prone. Sometimes it is literally impossible to keep the TCP machinery on the applications inside the enclave and the remote client/endpoint in sync just like each side expects the other to behave. This applies especially in the failure conditions and breaks proper error handling in a lot of applications.
To do better, we were going to have to go deeper into the networking stack than TCP. A kernel of an idea slowly started forming - what if we proxy whole TCP packets?
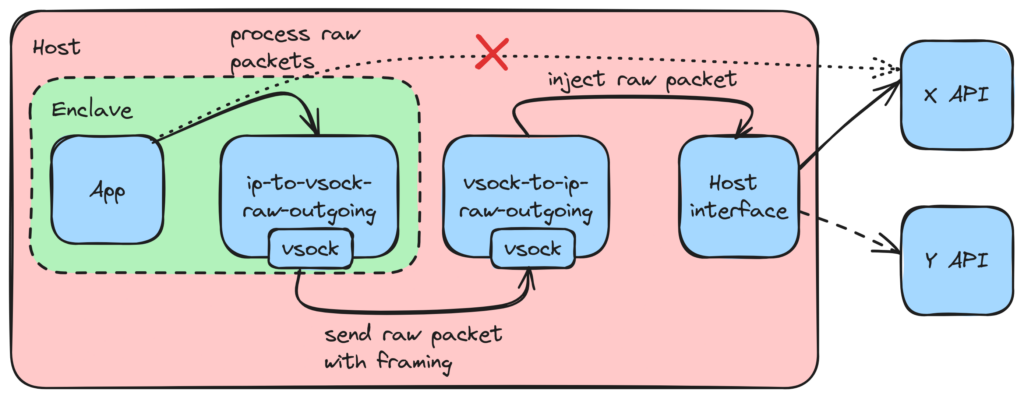
All of a sudden, all the TCP problems disappear because the proxies do not terminate TCP connections or generate TCP packets of their own, everything is done by the application and the endpoint. The proxies themselves would behave purely like routers, truly invisible to applications operating on the TCP level. And we were fairly confident it could be done, after all, Wireshark exists and works.
Diving into the Linux networking stack
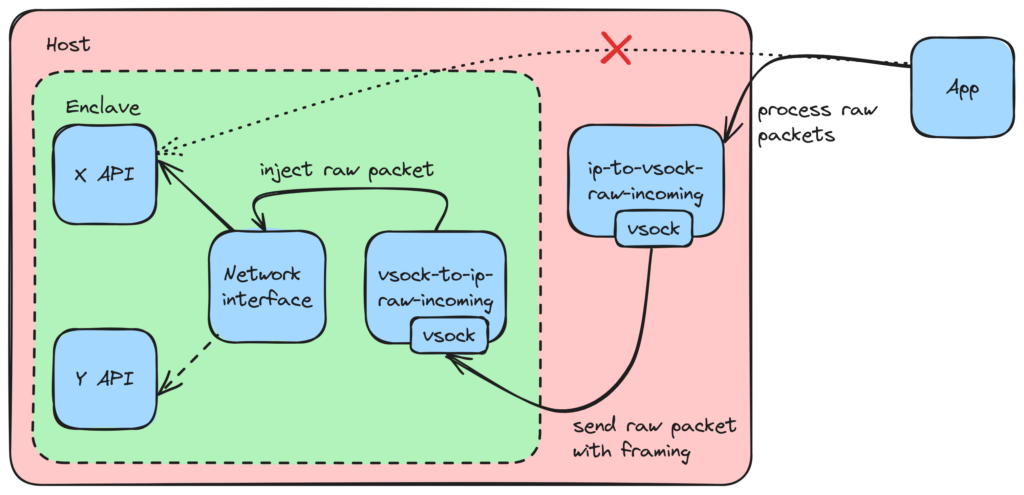
We took Wireshark as a starting point to figure out how to intercept packets. A quick search led us to AF_PACKET and SOCK_RAW. It allows interception of Ethernet frames and handles them in user space (our proxy here). A bit overkill since we don't need the Ethernet headers but it works.
Some experimenting and more spelunking in the man pages led us to the AF_INET and SOCK_RAW combination which does exactly what we need. It allows intercepting (technically copying, and yes it is important) IP packets which can be proxied to the Internet by tunneling through the vsock interface. Additionally, it lets us inject TCP packets into the networking stack so we can actually send the packets to the remote endpoint after proxying.
And voila!
INFO[2024-01-01T07:28:11Z] program started program=curl
* Trying 1.1.1.1:80...
* Connected to 1.1.1.1 (1.1.1.1) port 80 (#0)
> GET / HTTP/1.1
> Host: 1.1.1.1
> User-Agent: curl/7.81.0
> Accept: */*
>
* Mark bundle as not supporting multiuse
< HTTP/1.1 301 Moved Permanently
< Server: cloudflare
< Date: Tue, 01 Jan 2024 07:28:13 GMT
< Content-Type: text/html
< Content-Length: 167
< Connection: keep-alive
< Location: https://1.1.1.1/
< CF-RAY: 85127e8dbaee178a-MAA
<
<html>
<head><title>301 Moved Permanently</title></head>
<body>
<center><h1>301 Moved Permanently</h1></center>
<hr><center>cloudflare</center>
</body>
</html>
* Connection #0 to host 1.1.1.1 left intact
INFO[2024-01-01T07:28:13Z] program exited program=curl
Let's try that in the other direction now with a similar setup.
# queries the attestation server inside the enclave
$ curl <ip>:1300
curl: (7) Failed to connect to <ip> port 1300 after 366 ms: Connection refused
Oops.
Well, here's where the distinction between intercepting and copying matters. Inside the enclave, packets go nowhere by default anyway, so copying does the same job as intercepting. But on the host, simply copying leads to the host also handling the same packet, usually leading to ECONNREFUSED since there's likely nothing listening on the host.
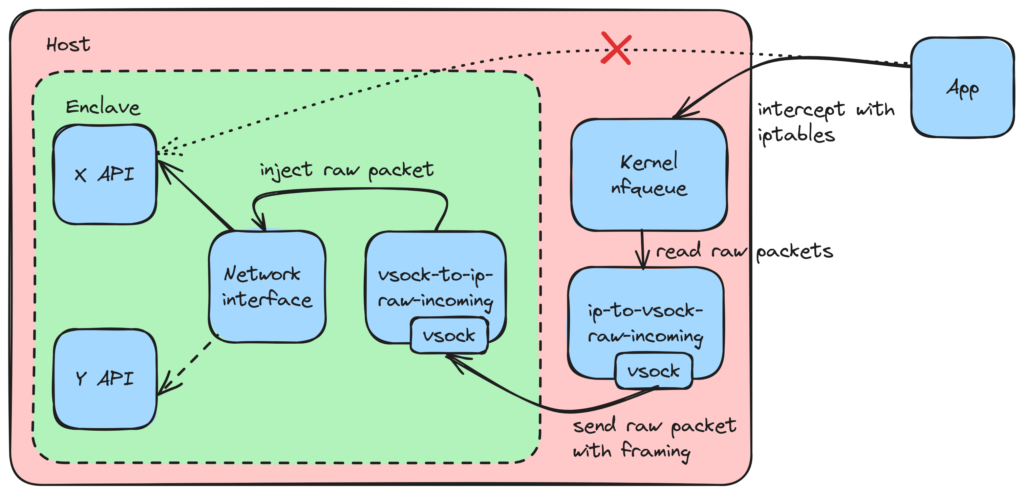
Back to more spelunking to find a way to actually intercept packets. We finally came across the netfilter_queue (nfqueue/nfq) subsystem which lets you intercept packets matching iptables rules.
As a bonus, there is a Rust library abstracting out netlink sockets and other low level details needed to interact with it. Some quick changes later:
# queries the attestation server inside the enclave
$ curl <ip>:1300
Warning: Binary output can mess up your terminal. Use "--output -" to tell
Warning: curl to output it to your terminal anyway, or consider "--output
Warning: <FILE>" to save to a file.
And we're done!
Are we though?
Gateways were deployed with the new proxies for the pilot with Bonfida and to our surprise, the pages took minutes to load. This was a significant regression from the old TCP proxies where pages would load in seconds and the bottleneck was usually IPFS retrieval. A benchmark of the proxies revealed the issue:
There is a significant bandwidth degradation on outbound traffic from the enclave!
But hey, it seems like the problem doesn't really exist on the side using nfqueue. We'll just replace our raw socket interception with nfqueue and we should be good, right? Right?
… continues in the next part as we dive deeper into the rabbit hole
Follow our official social media channels to get the latest updates as and when they come out!